What is Circle Sequencing?
Circle sequencing represents a pivotal progression in library preparation protocols for high-throughput sequencing, effectively expediting advancements within the expansive domain of genomic research. This innovative protocol diverges from the conventional linear sequencing methodologies, placing emphasis instead on the formulation of vigorous circular DNA templates derived from genomic DNA. This innovative mechanism provides heightened efficiency and notably improved error correction capabilities, positioning it as an essential asset within diverse scientific arenas such as cancer genomics, immunogenetics studies, microbial diversity exploration, and environmental sampling techniques. The following comprehensive discourse aims to delve intricately into the integrative principles, broadened applications, and profound benefits proffered by Circle-seq. Moreover, this disquisition will delineate the bioinformatics analysis particularly associated with this technique, underscoring its indubitable implication within contemporary genomic research methodologies.
Principle of Circle-Seq
Circularization of DNA Templates
Circle sequencing constitutes a paradigm shift in high-throughput sequencing techniques, providing a unique platform for genomic research. Central to this method is the fabricating of circular DNA molecules from genomic DNA. This intricate process commences with the fragmentation of genomic DNA into more manageable units, usually averaging 150 base pairs in length. Following this, the DNA motifs are phosphorylated and then denatured, priming them for the circularization process.
The act of circularization is catalyzed by enzymes, particularly CircLigase II ssDNA ligase, creating a lasso-like DNA configuration. Any excess, unstructured DNA is eliminated through an exonuclease cleaning action, ensuring the integrity of the remaining circular DNA templates. The end product is an efficiently prepared database for genomic exploration, epitomizing the transformative potential of Circle sequencing in genomics research.
Rolling Circle Amplification
Subsequent to DNA circularization, an approach known as rolling circle amplification (RCA) is enacted to multiply the circular templates. This involves attaching exonuclease-resistant random primers to the circular DNA and activating the augmentation procedure with enzymes like the Phi29 DNA polymerase. The RCA technique yields elongated concatemeric DNA chains containing numerous tandem repetition of the original template sequence, thereby considerably magnifying the DNA and boosting the sequencing signal.
High-Throughput Sequencing
Upon the generation of multiple copies of circular templates via RCA, these amplified forms are further subjected to sequencing. Generally, this sequencing is conducted through high-efficiency sequencing platforms that include, but are not limited to, Illumina MiSeq or HiSeq systems. Bi-directional or paired-end reads are subsequently created which enables the sequencing of both termini of the DNA fragments. This crucial step ensures the enhancement of the gross informational yield from each DNA molecule, thereby bolstering the precision and trustworthiness of the resultant sequencing data.
Take the Next Step: Explore Related Services
eccDNA Sequencing (Circle-seq)
eccDNA Methylation Sequencing Service
Discover More: Recommended Reads
Detailed Workflow of Circle-seq
The Circle-seq methodology comprises several intricate steps, exemplified herein, to ensure precise delineation of off-target loci:
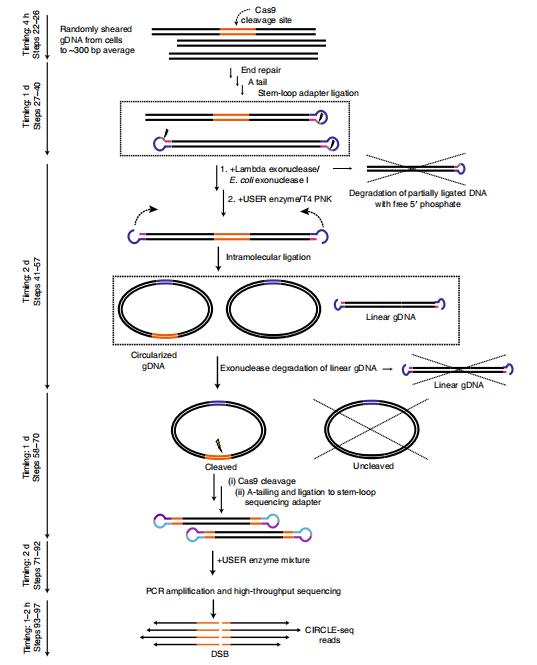
DNA Fragmentation: Genomic DNA undergoes fragmentation via physical means such as sonication or enzymatic cleavage to yield fragments of predetermined lengths.
Purification: The fragmented DNA is purified to eliminate potential contaminants that might impede the circularization process, typically employing Agencourt AMPure XP beads.
Circularization:
a. Blunt-End Ligation: Purified DNA fragments undergo treatment to generate blunt ends, thereby facilitating circularization. This process involves the utilization of DNA repair enzymes in conjunction with blunt-end ligation.
b. Circular DNA Enrichment: Circular DNA entities are enriched from the amalgam of linear and circular DNA molecules. This phase frequently entails exonuclease treatment to degrade any residual linear DNA fragments, leaving behind circularized DNA moieties.
In Vitro Cleavage and Sequencing Library Preparation:
a. In Vitro Cleavage: The enriched circular DNA is subjected to the genome-editing nuclease (e.g., CRISPR-Cas9) in vitro. The nuclease induces double-strand breaks (DSBs) at both target and off-target sites within the circular DNA.
b. DNA End Repair and A-tailing: The cleaved DNA fragments undergo end repair to generate blunt ends, followed by adenylation of the 3′ termini, rendering them amenable for adapter ligation.
c. Adapter Ligation and Amplification: Sequencing adapters are ligated to the adenylated DNA fragments, subsequently amplified via polymerase chain reaction (PCR). This stage enriches the cleaved fragments, which now harbor information pertaining to both target and off-target cleavage sites.
Next-Generation Sequencing (NGS): The prepared library undergoes NGS, yielding millions of reads corresponding to the DNA fragments cleaved by the nuclease.
Bioinformatics Analysis: The sequencing data undergo scrutiny via specialized bioinformatics pipelines. Tools such as BWA and SAMtools facilitate alignment of the reads to a reference genome, enabling identification of DSBs at both on-target and off-target loci.
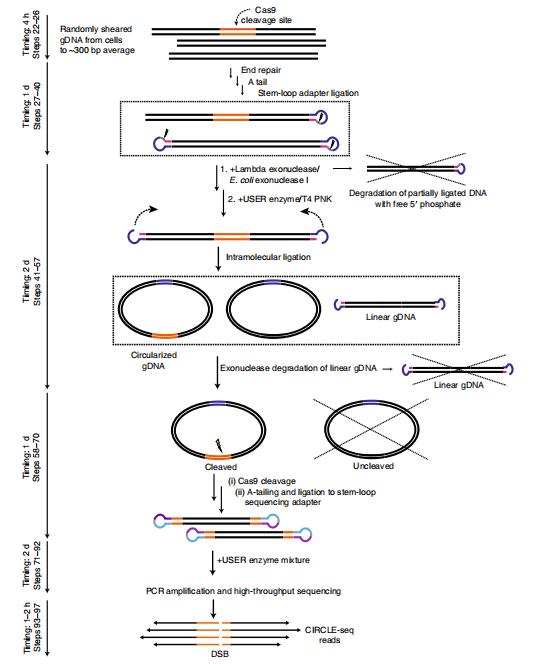 Overview of CIRCLE-seq workflow.
Overview of CIRCLE-seq workflow.
Circle-Seq Analysis
Efficiency and Error Correction
Tools for extrachromosomal DNA (ecDNA) research have advanced notably with the advent of Circle-seq methodology. Circle-seq, distinguished by its efficacy and error-correction capabilities when juxtaposed with conventional barcoding approaches, stands as a cornerstone in contemporary molecular investigations.
Efficiency, denoting the ratio of consensus bases generated to the total bases utilized, constitutes a pivotal metric in assessing sequencing methodologies. Under ideal conditions, wherein read families uniformly comprise three members, an efficiency benchmark of 33% is attainable. However, pragmatic considerations, encompassing the variance in circular DNA lengths and the employment of paired-end reads, lead to a marginally diminished efficiency.
Notably, CD Genomics has achieved an efficiency milestone of 20.2% in Circle-seq applications. This achievement signifies the derivation of one consensus base for every five bases engaged in sequencing endeavors. Contrastingly, conventional barcoding techniques typically exhibit efficiencies within the range of 1-8%. For instance, standard barcoding and duplex barcoding methodologies yield consensus sequences with efficiencies of 3.0% and 0.8%, respectively.
The superior efficiency characteristic of Circle-seq not only engenders the acquisition of enhanced quality data but also underpins a reduction in overall investigative costs. Thus, Circle-seq emerges as an indispensable tool in the arsenal ecDNA researchers, heralding a paradigm shift in molecular exploration.
Robustness Across Experimental Conditions
Circle sequencing stands out as a formidable tool owing to its resilience under diverse experimental conditions. Unlike barcoding methodologies, which necessitate meticulous manipulation of the ratio between barcoded input molecules and total reads, circle sequencing exhibits steadfast efficiency irrespective of the scale of the input library or the magnitude of generated reads. This exceptional robustness stems from the inherent physical linkage of reiterated sequences within individual read families, thus obviating the inherent variability associated with sampling from a complex mixture. Such intrinsic stability elevates circle sequencing as a reliable choice for molecular investigations across a spectrum of research settings.
Applications in Genomic Research
Circle sequencing emerges as a pivotal tool in scenarios demanding unparalleled accuracy and efficacy. In the realm of cancer profiling, for instance, the method’s capacity to furnish high-fidelity, error-corrected datasets assumes critical significance in discerning rare mutations and elucidating tumor heterogeneity. Likewise, within the domain of immunogenetics, circle sequencing offers a conduit for probing the intricacies of immune receptor repertoires, thereby illuminating immune responses and underlying disease mechanisms.
Moreover, circle sequencing finds resonance in microbial diversity investigations and environmental sampling endeavors. The method’s exceptional efficiency and resilience facilitate the identification and characterization of elusive microbial species and intricate microbial communities, which often elude detection by conventional sequencing modalities. This multifaceted utility positions circle sequencing as a cornerstone in molecular explorations spanning diverse disciplines.
Circle-seq Bioinformatics Steps
1. Read Mapping and Alignment
The sequence reads produced via Circle-seq experiments are scrutinized, positioned, and coordinated with the reference genome via application of specialized bioinformatics tools like the Burrows-Wheeler Aligner (BWA) and Sequence Alignment/Map (SAMtools). This crucial step facilitates the precise identification and subsequent classification of circular DNA elements within the genome’s intricate architecture, thus ensuring a deeper understanding of our genetic fabric.
2. Identification of Circular DNA Elements
Circular DNA motifs are discerned according to their distinct alignment blueprints and distribution of sequence reads. Employing refined bioinformatics algorithms serves to set apart circular DNA elements from their linear genomic counterparts, thereby enabling accurate positioning and intricate profiling of circular genomic structures.
3. Functional Annotation and Interpretation
Given the identification of the circular DNA elements, the task then shifts to their functional annotation and interpretation to shed light on their biological relevance. This consists of associating the circular DNA elements with distinct genomic features, for instance, gene promoters, enhancers, and regulatory elements, which yields insights into their probable roles in gene regulation and genome stability.
Advantages of Circle-seq
Circle-seq has emerged as an instrumental molecular technique, boasting significant advantages over classical sequencing methods, largely owing to its capacity to enrich circular DNA molecules selectively. This capability, in turn, enables an in-depth exploration of genomic components and uncovers their functional implications.
1. Enhanced Sensitivity and Specificity
A salient advantage attributed to Circle-seq lies in its unparalleled sensitivity and specificity in pinpointing circular DNA constituents within complex genomic landscapes. Leveraging a selective enrichment approach for circular DNA fragments, Circle-Seq mitigates confounding signals and false-positive results, thus augmenting the accuracy of genomic profiling. The technology’s heightened specificity ensures the reliable detection of circular DNA elements, transcending the limitations imposed by scarce abundance. Consequently, Circle-Seq is especially appropriate for the investigation of infrequent genomic events and structural aberrations.
2. Comprehensive Genomic Coverage
Circle-seq stands as an instrumental technology in the domain of molecular biology, providing an inclusive genomic coverage, and equipping scientists with the capacity to identify various circular DNA elements. These include ecDNA, circRNA, and a plethora of other circular genomic fragments. In contrast to conventional sequencing methodologies, which primarily lay emphasis on linear DNA trajectories, Circle-seq extends a comprehensive perspective on the genomic circular landscape. This not only maps the genomic architecture in its totality but also facilitates unearthing of previously unidentified, integral insights on genomic organization.
3. Versatility and Flexibility
Paralleling a considerable asset of the Circle-seq methodology is its versatile deployment potential in genomic studies. Exhibiting adaptability to an array of experimental designs and sample typologies, Circle-seq is aptly suited to address a broad range of research queries and targets. Its application extends from the examination of oncological molecular processes, the scrutiny of chromatin topography to the regulatory analysis of RNA. Further elevating Circle-seq’s versatility is its potential integration with other molecular methodologies. Integration with techniques such as chromatin immunoprecipitation (ChIP) and RNA sequencing (RNA-seq) harnesses the opportunity to glean additional perspectives into genomic function and its regulation mechanisms.
4. Cost-effectiveness
Incorporating both technical and economic efficiency, Circle-seq distinguishes itself from more conventional sequencing methods. Its selective enrichment of circular DNA molecules curtails the need for profound sequencing depth to achieve exhaustive genomic coverage. This, in turn, effectively mitigates the overall expenses associated with sequencing. Consequently, Circle-seq emerges as a viable and cost-effective solution for extensive genomic research activities and analyses involving numerous samples. Such efficient financial management could indeed be invaluable in contexts where budgetary constraints pose a significant challenge to the use of high-priced sequencing methodologies.